
Slimme opmaak tutorials
Dit document is kladversie 0.1
Gebruikte dataset
De tutorials maken gebruik van een recent gepubliceerde 'slimme-opmaak'-dataset: het krantenarchief van de eerste Wereldoorlog. Deze website bevat een gepagineerde lijst van meer dan 50 000 kranten. De Linked Data bevat twee onderdelen: ten eerste is er de domein-specifieke metadata, zoals de metadata over een krant. Ten tweede mag een machine niet enkel data van één pagina terugvinden, maar moet ook verder kunnen zoeken naar de volgende of vorige pagina’s met behulp van hypermedia controls.
Om de slimme opmaak van de krantendataset te vinden, ga je naar een krant zoals deze krant en klik je met je rechtermuisknop op ‘Bekijk paginabron’ (View page-source). Bovenaan zie je een script-tag met de Linked Data in JSON-LD formaat. Deze vorm van slimme opmaak noemt 'rich snippets'.
- Domein-specifieke metadata
-
De domein-specifieke metadata van een krantenpagina wordt als volgt weergegeven:
{ "@context": [ "http://schema.org/", { "dcterms": "http://purl.org/dc/terms/", "rdfs": "http://www.w3.org/2000/01/rdf-schema#", "languageLabel": { "@id": "schema:inLanguage", "@type": "xsd:String" }, "title": "dcterms:title", "xsd": "http://www.w3.org/2001/XMLSchema#", "sio": "http://semanticscience.org/resource/", "pageNumber": { "@id": "sio:SIO_000787", "@type": "xsd:String" }, "topicOf": { "@id": "http://xmlns.com/foaf/0.1/topicOf", "@type": "@id" }, "createdDate": { "@id": "dcterms:created", "@type": "xsd:date" } }, "@id": "https://hetarchief.be/pid/6688g8g656/7", "@type": "schema:CreativeWork", "datePublished": "1914-01-31", "headline": "Semaine religieuse du diocèse de Liège", "languageLabel": "fr", "publisher": "KADOC", "title": "Semaine religieuse du diocèse de Liège", "createdDate": "1914-01-31", "topicOf": [ "http://anet.be/record/abraham/opacbnc/c:bnc:5326" ], "pageNumber": "7" }Snippet 1: eigenschappen van een krantenpagina beschreven volgens semantische standaarden.Bovenstaande snippet toont hoe metadata zoals titel, uitgever, datum van creatie etc. worden gemapt naar datastandaarden in de
@context, e.g. DCTerms, FOAF, schema.org. Deze metadata is in lijn met de design-principes van Linked Data:- Gebruik HTTP URI's (webadressen) om zaken te benoemen: Een krant heeft bijvoorbeeld volgend webadres:
https://hetarchief.be/pid/6688g8g656. Pagina 7 van deze laatste heeft volgend webadres:https://hetarchief.be/pid/6688g8g656/7 - Wanneer iemand dit webadres opzoekt, geef relevante informatie terug: Dankzij rich snippets is er niet alleen mens-leesbare (HTML), maar ook machine-leesbare informatie (JSON-LD) die semantische standaarden volgt.
- Voeg links naar andere relevante databronnen: Er is een verwijzing opgenomen naar de catalogus van Belgische kranten (ABRAHAM). Deze beschrijft diezelfde krant en bevat dus andere relevante informatie.
Een eindgebruiker kan makkelijk informatie terugvinden in een website, onder andere door de verscheidene navigatie-middelen die ter beschikking gesteld worden: een overzichtpagina, zoekbalk, paginering etc. In volgende paragraaf bekijken we hoe deze stuurmiddelen, zogenaamd hypermedia controls, ook voor een machine nuttig zijn en hoe deze toegepast worden voor paginering.
- Gebruik HTTP URI's (webadressen) om zaken te benoemen: Een krant heeft bijvoorbeeld volgend webadres:
- Hypermedia controls
-
Hypermedia controls laten toe dat een gebruiker hints ziet om meer informatie te vinden. Een kaart laat bijvoorbeeld toe om in een bepaald geografisch gebied te zoeken. Voor de gebruikte dataset van kranten werd er gekeken wat er reeds bij elke krant zichtbaar is. In figuur 1 zie je dat de krant een verwijzing heeft naar een vorige en volgende krant. Bijgevolg is de volledige collectie aan elkaar gelinkt.
 Figuur 1: een krant bevat mens-leesbare links naar de vorige en volgende krant.
Figuur 1: een krant bevat mens-leesbare links naar de vorige en volgende krant.Voor een mens is het visueel logisch wat deze knoppen doen, maar een machine weet niet wat hier precies mee bedoeld wordt, behalve dat het links zijn. Om dit semantisch te beschrijven met termen die een machine wel kan verstaan wordt er gekeken naar de veelgebruikte Web API standaard Hydra. Deze zegt dat een volgende pagina wordt aangeduid met de term
http://www.w3.org/ns/hydra/core#nexten vice versahttp://www.w3.org/ns/hydra/core#previous. Deze manier van annoteren wordt ook door de Vlaamse Overheid gepromoot in de generieke hypermedia standaard binnen het Open Standaarden voor Linkende Organisaties (OSLO) traject.Snippet 2 toont hoe paginering in een rich snippet is beschreven.
@idverwijst naar het webadres van het document van de krant en dus niet het webadres van de krant zelf.Nextenpreviousverwijzen door naar het volgende en vorige document.{ "@context": "http://www.w3.org/ns/hydra/context.jsonld", "@id": "https://hetarchief.be/nl/media/semaine-religieuse-du-dioc%C3%A8se-de-li%C3%A8ge/L1eWGUl8QYiOdfGQhvSWrwVx", "previous": "https://hetarchief.be/nl/media/semaine-religieuse-du-dioc\u00e8se-de-li\u00e8ge/Q2eHAKighhXbNhWjXaGCsDA1", "next": "https://hetarchief.be/nl/media/semaine-religieuse-du-dioc\u00e8se-de-li\u00e8ge/qOVsIWKTfhXlqaNUQ4cQZcOY" }Snippet 2: een krant bevat machine-leesbare links naar de vorige en volgende krant.Tot slot willen we nog even aankaarten hoe krachtig deze hypermedia links zijn. Deze links laten toe om met een eenvoudig script alle data te downloaden wat voorheen enorm veel manueel werk vroeg (cfr. Web scraping). Onderstaande GIF demonstreert hoe met één commando (LDFetch) alle data als een stream gedownload kan worden. LDFetch leest het document dat opgegeven werd in en geeft alle gevonden triples terug. Met de parameter
-pkan een predikaat meegegeven worden waarvan de eventuele gevonden waarde gevolgd moet worden. Zo ontstaat er een ketting van documenten die opgevraagd worden. Dit commando is generiek gebouwd waardoor het ook op andere datasets gebruikt kan worden.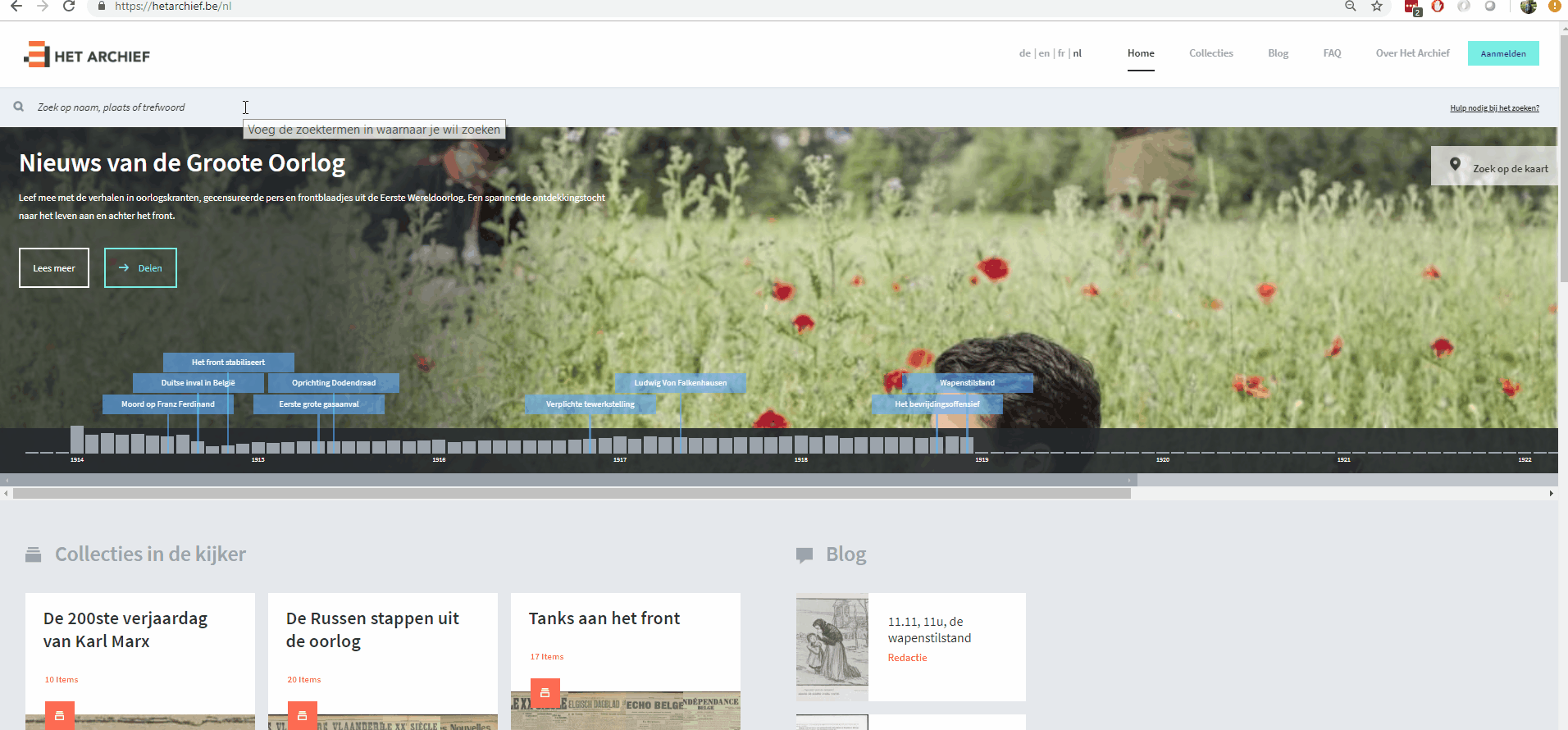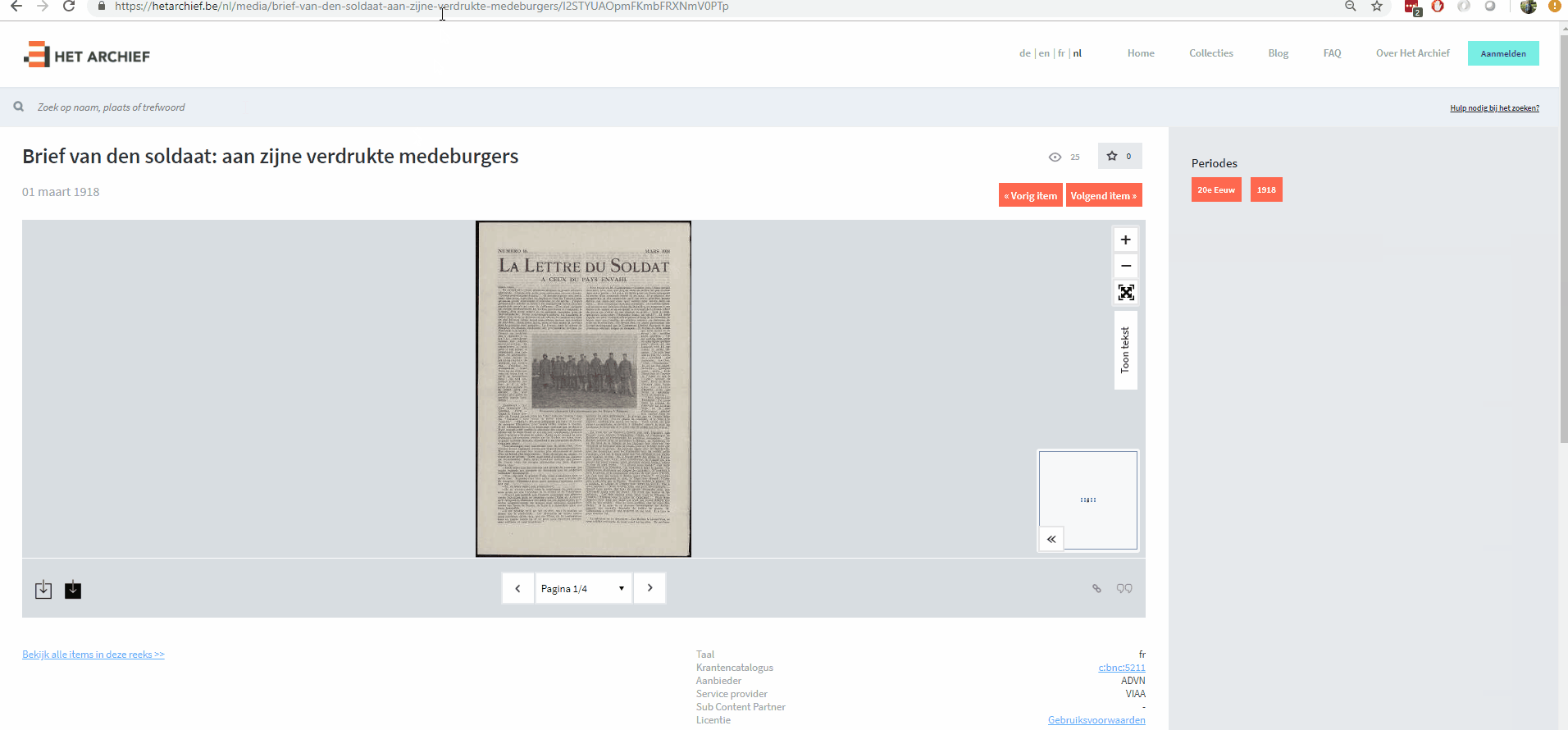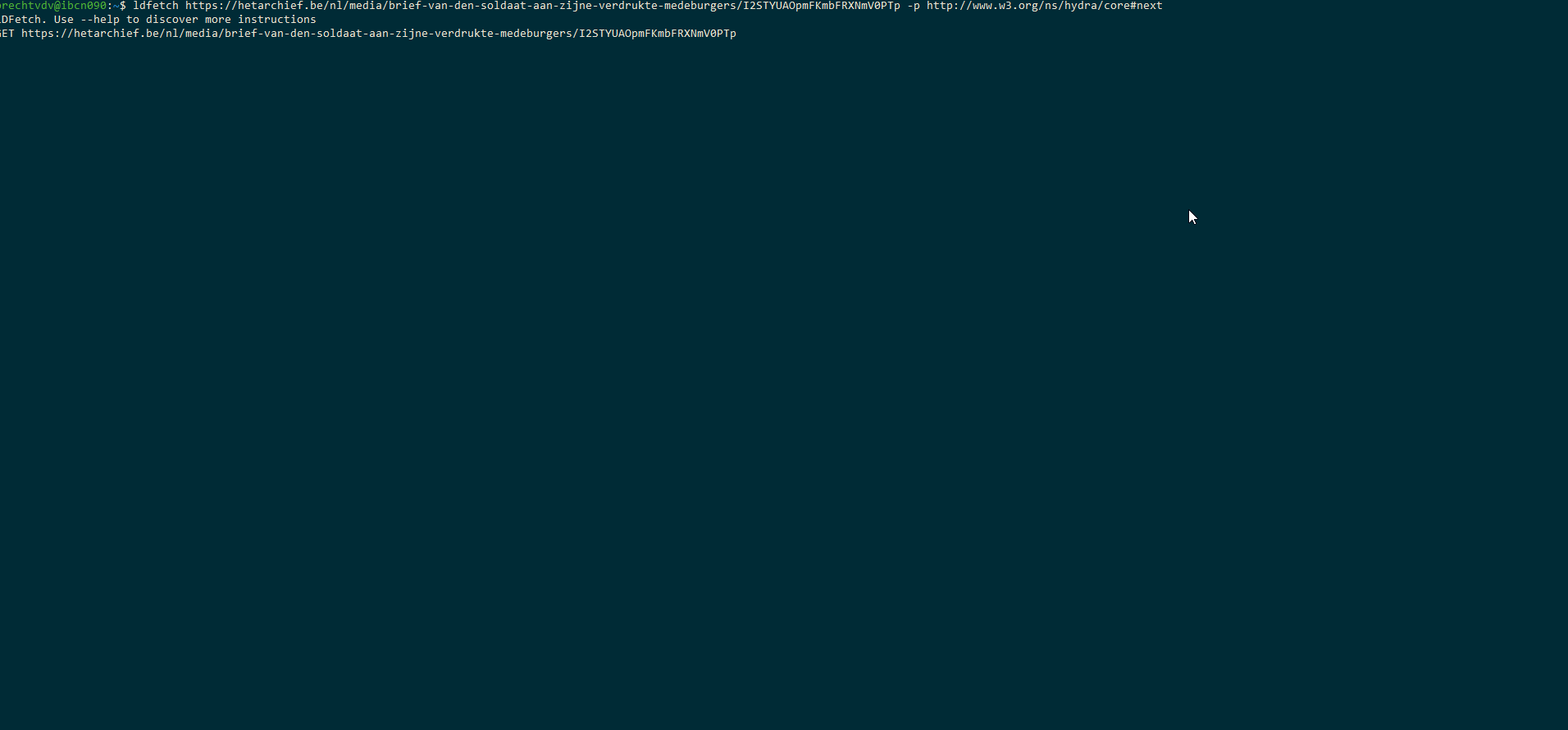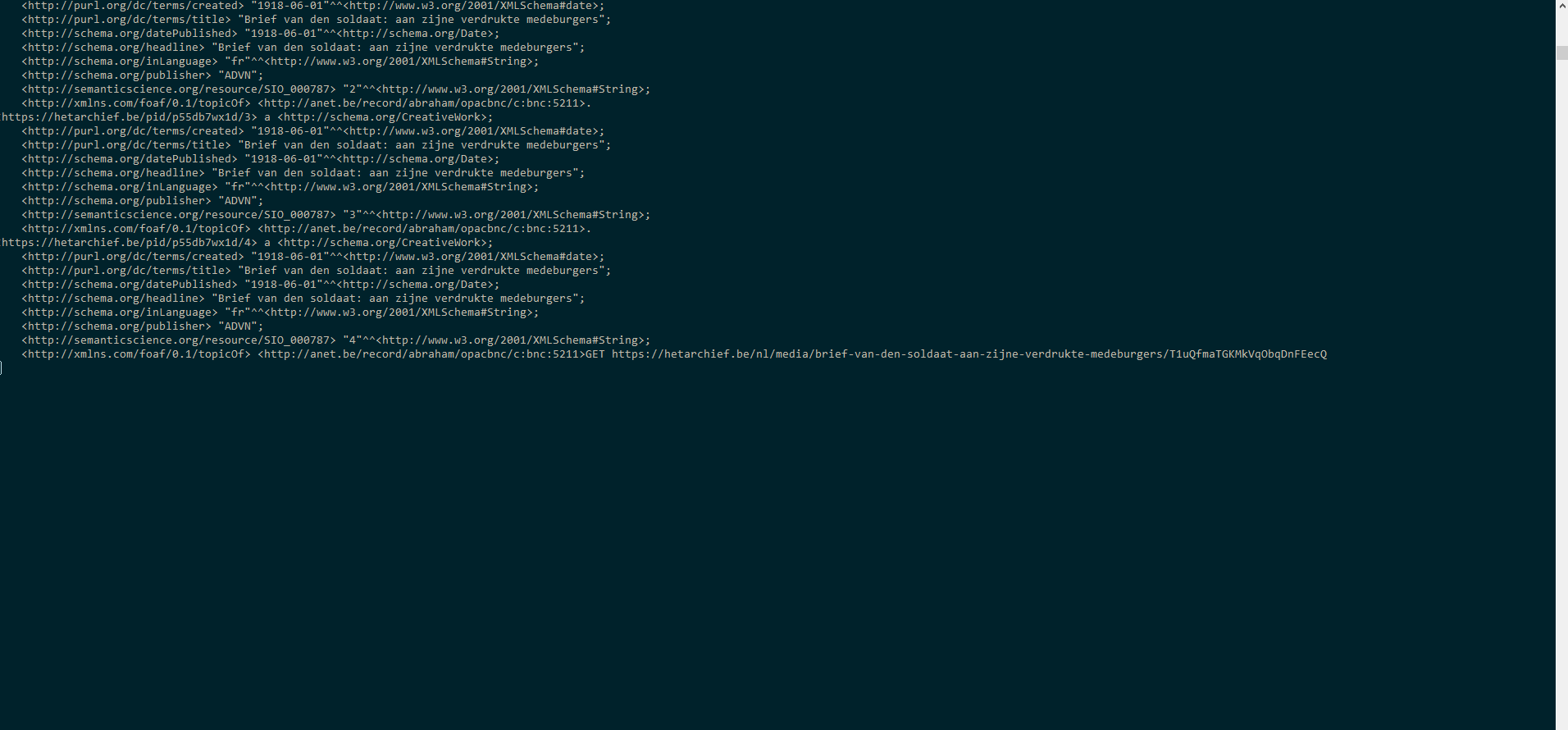 Met behulp van één commando kan de volledige dataset als een stream gedownload worden.
Met behulp van één commando kan de volledige dataset als een stream gedownload worden.
In volgend hoofdstuk bespreken we hoe een gebruiker een gepagineerde dataset kan downloaden als een spreadsheet.
Tutorial 1: uw website als een spreadsheet
Linked Data gebruikt het Resource Description Framework (RDF) als model om data op te stellen. Elke stukje data wordt als een triple (subject-predikaat-object) beschreven waarbij subject en object een node zijn en het predikaat de verbinding tussen die twee nodes. RDF data stelt dus een graaf van nodes en verbindingen voor. Een spreadsheet daarentegen werkt met een tabulair model van rijen en kolommen.
Om de graaf van gelinkte data naar een tabel te converteren kan de SPARQL query-taal gebruikt worden. Een SPARQL-query beschrijft een bepaalde vraag aan de hand van patronen waaraan het resultaat moet voldoen. Om een voorbeeld te geven toont snippet 3 hoe alle kranten opgevraagd kunnen worden met in de eerste kolom de identificator van de krant en in de tweede kolom de datum van publicatie. Dit brengt ons meteen waarom we een SPARQL-query gebruiken om een spreadsheet op te bouwen: wat er vermeld staat in de SELECT-clausule stelt de kolommen voor van de spreadsheet. Bijgevolg stelt elk gevonden resultaat een rij van de tabel voor.
Meer informatie over SPARQL-queries kan hier gevonden worden.
SELECT ?krant ?publicatiedatum
WHERE {
?krant <http://www.w3.org/2000/01/rdf-schema#type> <http://schema.org/Newspaper> .
?krant <http://schema.org/datePublished> ?publicatiedatum .
}
Deze tutorial maakt gebruik van Codepens om code uit te voeren. Een Codepen is een sandbox waarbinnen HTML, CSS en JavaScript gedraaid kan worden. Dit laat toe dat iedereen makkelijk in de code kan duiken om bepaalde technieken te leren. Om de data op te vragen maken we gebruik van Comunica. Deze bibliotheek laat toe om verschillende soorten databronnen te bevragen. Binnen deze tutorial bevragen we de gepagineerde krantencollectie en extraheren we hieruit een CSV-bestand.
See the Pen Converteren van website naar spreadsheet by Brecht Van de Vyvere (@brechtvdv) on CodePen.
In volgende hoofdstuk beschrijven hoe de dataset bevraagd kan worden met behulp van GraphQL-LD.
Tutorial 2: uw website query'en
De doelstelling van deze tutorial is om aan te tonen hoe je Linked Open Data van een webpagina op een makkelijke manier kunt ophalen zodat deze herbruikbaar is voor andere doeleinden. SPARQL is de meest gebruikte manier om Linked Open Data te bevragen, maar heeft als heikel punt dat het resultaat een verzameling van triples is. Recent werd hierop ingespeeld met een object georiënteerde taal LDflex die we hier niet verder bespreken. Bij Web ontwikkelaars gaat de voorkeur om te werken met JSON-objecten. Comunica biedt hier ook een antwoord op dankzij GraphQL-LD. In volgende paragraaf beschrijven een ontwikkelaar dit kan gebruiken om een JSON-object te genereren uit een webpagina. Comunica heeft een uitgebreide documentatie om dit te installeren op zowel de server-side, client-side als command line (cli). Binnen deze tutorial demonstreren we hoe de command line gebruikt kan worden voor GraphQL commando's. Dit heeft als voordeel dat de data doorgestuurd kan worden naar een andere applicatie. Open een terminal en voer volgend commando uit om Comunica globaal te installeren (merk op dat je NPM geïnstalleerd moet hebben):
$ [sudo] npm install -g @comunica/actor-init-sparql
query @single(scope: all) {
graph
id
type
... on Krant {
titel
paginas {
id
type
}
}
}
{
"@context": {
"titel": "http://purl.org/dc/terms/title",
"type": "http://www.w3.org/1999/02/22-rdf-syntax-ns#type",
"Krant": "http://schema.org/Newspaper",
"paginas": "http://schema.org/hasPart"
}
}
comunica-sparql https://nieuwsvandegrooteoorlog.hetarchief.be/nl/media/verordeningsblad-voor-het-etappengebied-van-het-4e-leger/F1tQSYoRdEmTSnhWmwIE82be -q 'query @single(scope: all){ graph id type ... on Krant { titel paginas { id type } } }' -c graphql-config.json -i graphql -t tree
{
"id": "https://hetarchief.be/pid/804xg9gs1q",
"type": "http://schema.org/Newspaper",
"graph": "https://nieuwsvandegrooteoorlog.hetarchief.be/nl/media/verordeningsblad-voor-het-etappengebied-van-het-4e-leger/F1tQSYoRdEmTSnhWmwIE82be",
"paginas": {
"type": "http://schema.org/CreativeWork",
"id": "https://hetarchief.be/pid/804xg9gs1q/1"
},
"titel": "Verordeningsblad voor het Etappengebied van het 4e Leger"
}